
Requirements in software engineering are a living thing. As we develop the software or as the software is used in day to day business, new perspectives are revealed that require us to adjust the original requirements. As the requirements change, so does the planning of the software and this often causes friction between the stakeholders and the engineers, therefore, we must develop our coping mechanisms to accommodate this constant change to minimize this friction. Let us discuss the reasons behind the change and how can engineers do requirements negotiation.
Why do requirements change?
As the business circumstances change or new facts emerge, so do the requirements for the software. While this change of requirements is something mainly disliked, at the same time it is something that in most cases cannot be avoided or prevented. The very thing we need to do when requirements change is to get a clear understanding on all sides about the why. Why do we need to change the requirements. It is not easy to list all possible change categories, but most often you will see one of these root causes:
- New information has emerged about a previous assumption
- Management has decided to pivot the project direction
- There has been a change in the market (e.g. competition, new customer requirement, etc.)
- New legal requirement has come up
No matter the change reason, it is very important to understand the background so you know the importance of the change. When you know the why, chances are higher that you will empathize with the requestor, rather than thinking they did not do their job properly when writing them. This sets a better baseline on both sides when trying to find the best solution how to move forward.
What can we do when the requirements change?
As engineers, when we analyze a change request, we try to think it through all the perspectives that we can imagine. We think what do we need to do to implement a certain requirement, what can go wrong and how can we prevent it, what kind of quality measures we need to put in place, etc. This is a complex process with a lot of, usually unspoken, variables in it.
As an outcome of this process, we propose a solution and give a delivery estimation. Usually, this estimation is taken into calculation of the implementation timeline and is announced to stakeholders, turning it into a commitment for engineers. This is exactly where the problem arises. If the requirements change, the implementation needs to be re-planned, maybe re-worked if the work is in progress and chances of delivering on previously promised date start to decline, a fact very often dismissed by the business stakeholders. Often, change of the deadline is highly opposed and it becomes a blame game. From my experience, I have learned that:
Change of requirements is not the problem, the problem is the inadequate communication of the cost of the change
To escape this blame game, we need to do a fact based discussion laying all the cards on the table, show the viable options we have in front of us and guide the stakeholders into choosing the next step. This way we make sure that everyone is aware of the cost of the change and no one is blamed for not delivering on the promise.
The triangle of change
Before we discuss how the change of requirements can be negotiated, let us first understand the dimensions of change, which I like to call the triangle of change. When the requirements are estimated, engineers usually think of what needs to be done (the scope), the quality of the solution (automated testing) and come up with an estimation on how long will it take to implement the change. But, when the requirements change, there comes the triangle of change in play.
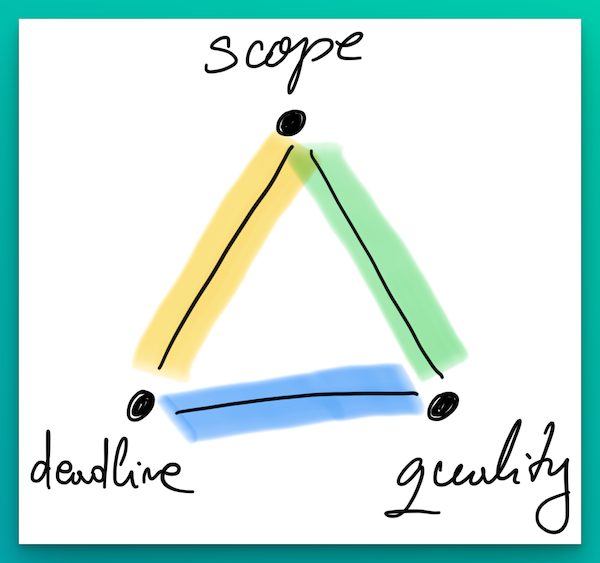
The triangle of change shows that one can hold at max to two of the points and has to sacrifice the third. Meaning, one can choose to:
- Hold on to scope and quality (green vertex) -> sacrifice deadline
- Hold on to scope and deadline (yellow vertex) -> sacrifice quality
- Hold on to deadline and quality (blue vertex) -> sacrifice scope
Once this is understood by all parties, then the negotiation can begin.
How to negotiate the requirements
It is also often the case that change is requested while holding the expectation to the same estimation, scope and quality standards. How can engineers address this situation constructively? This is the framework that I generally use:
- Listen to understand the motivation behind! You need to understand, why are the requirements changing now and how pressing this is.
- Ask if we can de-scope something else or extend the deadline. Out of the three dimensions of the triangle, you want to avoid lowering quality at any cost (this will haunt you back), so adjusting the scope or postponing the deadline is the most desired outcome.
- If you should hold onto the deadline, then see all the options you have to adjust the scope. Offer the requester a couple of alternatives together with the associated cost. Make it transparent, what decision leads to what outcome. Agree together!
- Communicate the “new agreement” openly to all stakeholders.
To illustrate this better, I will go through two scenarios to demonstrate the use of the framework:
Scenario 1: The engineer is working on integrating an online payments provider’s checkout process into an application. This work is estimated at 10 work days. The work is in progress at about 50% and will be finished in 5 days. And… here comes the product manager with a new announcement. The CEO has negotiated a better deal with another provider and you need to integrate this new one. How would I go from here?
- I would first asks questions to understand what exactly does this change mean. Do we need to drop the previous integration or do we need to complete it plus add the new integration. Ideally, I would also try to understand the rationale behind. When knowing the why, it is a lot easier to accept the change positively.
- I would ask for some time to analyze the integration process of the new provider. I would estimate what parts of the already done work needs to be dropped and what can be reused, thus estimating how much more time I would need to complete the integration of the new provider with the same quality and same scope. I calculate the delta and explain to the product manager what is the cost of this pivot.
- As implementing payments’ integration is a crucial feature for the product, I go ahead and analyze quickly if we can also do a feature breakdown and see if can deliver it in chunks, meaning still hitting the initial deadline with a smaller scope and then complete the rest of the work after the first release. So I come up with two alternative paths we may walk and their associated cost and outcome.
- Having gathered all these facts, I would have a talk with the product manager and present them all the options we have.
- Adjusting the scope and go live with a minimal version
- Extending the deadline to accommodate the new requirements
- Lowering the quality (I TRY TO AVOID THIS AT ALL COST)
- Try to agree together on one of the options, or if we cannot, then ask for further input from other stakeholders
- Communicate the decision in the team transparently so everyone is a ware what is happening.
Conclusion
Change is the only constant. During the development of a software, requirements change very often and getting comfortable living with the change will make your life easier as an engineer. Using the above mentioned negotiation framework can help you deal with those situations better and smoother agreement with your business stakeholders on changes and consequences with less stress and frustration.



